Package: PSMatch
Authors: Laurent Gatto [aut, cre] (ORCID: https://orcid.org/0000-0002-1520-2268), Johannes Rainer
[aut] (ORCID: https://orcid.org/0000-0002-6977-7147), Sebastian Gibb
[aut] (ORCID: https://orcid.org/0000-0001-7406-4443), Samuel Wieczorek
[ctb], Thomas Burger [ctb], Guillaume Deflandre [ctb] (ORCID: https://orcid.org/0009-0008-1257-2416)
Last modified: 2026-05-20 15:57:35.878907
Compiled: Wed May 20 16:16:09 2026
Introduction
This vignette is one among several illustrating how to use the
PSMatch package, focusing on the calculation and
visualisation of MS2 fragment ions. For a general overview of the
package, see the PSMatch package manual page
(?PSMatch) and references therein.
To illustrate this vignette, we will import and merge raw and identification data from the MsDataHub. For details about this section, please visit the Spectra package webpage.
Load the raw MS data:
spf <- MsDataHub::TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01.20141210.mzML.gz()
library(Spectra)
sp <- Spectra(spf)Load the identification data:
idf <- MsDataHub::TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01.20141210.mzid()## see ?MsDataHub and browseVignettes('MsDataHub') for documentation## loading from cache
id <- PSM(idf) |> filterPSMs()## Starting with 5802 PSMs:## Removed 2896 decoy hits.## Removed 155 PSMs with rank > 1.## Removed 85 shared peptides.## 2666 PSMs left.
id## PSM with 2666 rows and 35 columns.
## names(35): sequence spectrumID ... subReplacementResidue subLocationMerge both:
sp <- joinSpectraData(sp, id, by.x = "spectrumId", by.y = "spectrumID")## Warning in joinSpectraData(sp, id, by.x = "spectrumId", by.y = "spectrumID"):
## Duplicates found in the 'y' key. Only last instance will be kept!
sp## MSn data (Spectra) with 7534 spectra in a MsBackendMzR backend:
## msLevel rtime scanIndex
## <integer> <numeric> <integer>
## 1 1 0.4584 1
## 2 1 0.9725 2
## 3 1 1.8524 3
## 4 1 2.7424 4
## 5 1 3.6124 5
## ... ... ... ...
## 7530 2 3600.47 7530
## 7531 2 3600.83 7531
## 7532 2 3601.18 7532
## 7533 2 3601.57 7533
## 7534 2 3601.98 7534
## ... 68 more variables/columns.
##
## file(s):
## d1243b6fa91_7858In this example, we are going to focus the MS2 scan with index 1158 and its parent MS1 scan (index 1148, selected automatically with the filterPrecursorScan() function).
sp1158 <- filterPrecursorScan(sp, 1158)
plotSpectra(sp1158[1], xlim = c(400, 600))
abline(v = precursorMz(sp1158)[2], col = "red", lty = "dotted")
Calculating fragment ions
The MS2 scan was matched to the sequence SCALITDGR.
sp1158$sequence## [1] NA "SCALITDGR"The calculateFragments() simply takes a peptide sequence
as input and returns a data.frame with the fragment
sequences, M/Z, ion type, charge, position and the peptide sequence of
the parent ion. By default, carbamidomethylation of cysteines is
applied, but it can be turned off with the parameter
addCarbamidomethyl = FALSE.
calculateFragments(sp1158$sequence[2], addCarbamidomethyl = FALSE)## mz ion type pos z seq peptide
## 1 88.03931 b1 b 1 1 S SCALITDGR
## 2 191.04850 b2 b 2 1 SC SCALITDGR
## 3 262.08561 b3 b 3 1 SCA SCALITDGR
## 4 375.16967 b4 b 4 1 SCAL SCALITDGR
## 5 488.25373 b5 b 5 1 SCALI SCALITDGR
## 6 589.30141 b6 b 6 1 SCALIT SCALITDGR
## 7 704.32835 b7 b 7 1 SCALITD SCALITDGR
## 8 761.34981 b8 b 8 1 SCALITDG SCALITDGR
## 9 175.11895 y1 y 1 1 R SCALITDGR
## 10 232.14041 y2 y 2 1 GR SCALITDGR
## 11 347.16735 y3 y 3 1 DGR SCALITDGR
## 12 448.21503 y4 y 4 1 TDGR SCALITDGR
## 13 561.29909 y5 y 5 1 ITDGR SCALITDGR
## 14 674.38315 y6 y 6 1 LITDGR SCALITDGR
## 15 745.42026 y7 y 7 1 ALITDGR SCALITDGR
## 16 848.42945 y8 y 8 1 CALITDGR SCALITDGR
## 17 686.31778 b7_ b_ 7 1 SCALITD SCALITDGR
## 18 743.33924 b8_ b_ 8 1 SCALITDG SCALITDGR
## 19 329.15679 y3_ y_ 3 1 DGR SCALITDGR
## 20 543.28853 y5_ y_ 5 1 ITDGR SCALITDGR
## 21 656.37259 y6_ y_ 6 1 LITDGR SCALITDGR
## 22 727.40970 y7_ y_ 7 1 ALITDGR SCALITDGR
## 23 830.41889 y8_ y_ 8 1 CALITDGR SCALITDGR
## 24 157.10839 y1_ y_ 1 1 R SCALITDGR
## 25 214.12985 y2_ y_ 2 1 GR SCALITDGR
## 26 430.20447 y4_ y_ 4 1 TDGR SCALITDGRThe function also allows to generate fragment sequences with fixed
and/or variable modifications using the
PTMods::addFixedModifications() and
PTMods::addVariableModifications() functions from the
r BiocStyle::Biocpkg("PTMods") package.
With variable modifications, multiple sets of fragments are generated
based on the peptide-modifications combinations available. The fragments
can be traced to their parent ion by checking the peptide
column. A fragment can have multiple modifications.
var_seq <- PTMods::addVariableModifications(sp1158$sequence[2],
variableModifications = c(C = 57.02146, T = 79.966)
)
calculateFragments(var_seq)## mz ion type pos z seq peptide
## 1 88.03931 b1 b 1 1 S SCALITDGR
## 2 191.04850 b2 b 2 1 SC SCALITDGR
## 3 262.08561 b3 b 3 1 SCA SCALITDGR
## 4 375.16967 b4 b 4 1 SCAL SCALITDGR
## 5 488.25373 b5 b 5 1 SCALI SCALITDGR
## 6 589.30141 b6 b 6 1 SCALIT SCALITDGR
## 7 704.32835 b7 b 7 1 SCALITD SCALITDGR
## 8 761.34981 b8 b 8 1 SCALITDG SCALITDGR
## 9 175.11895 y1 y 1 1 R SCALITDGR
## 10 232.14041 y2 y 2 1 GR SCALITDGR
## 11 347.16735 y3 y 3 1 DGR SCALITDGR
## 12 448.21503 y4 y 4 1 TDGR SCALITDGR
## 13 561.29909 y5 y 5 1 ITDGR SCALITDGR
## 14 674.38315 y6 y 6 1 LITDGR SCALITDGR
## 15 745.42026 y7 y 7 1 ALITDGR SCALITDGR
## 16 848.42945 y8 y 8 1 CALITDGR SCALITDGR
## 17 686.31778 b7_ b_ 7 1 SCALITD SCALITDGR
## 18 743.33924 b8_ b_ 8 1 SCALITDG SCALITDGR
## 19 329.15679 y3_ y_ 3 1 DGR SCALITDGR
## 20 543.28853 y5_ y_ 5 1 ITDGR SCALITDGR
## 21 656.37259 y6_ y_ 6 1 LITDGR SCALITDGR
## 22 727.40970 y7_ y_ 7 1 ALITDGR SCALITDGR
## 23 830.41889 y8_ y_ 8 1 CALITDGR SCALITDGR
## 24 157.10839 y1_ y_ 1 1 R SCALITDGR
## 25 214.12985 y2_ y_ 2 1 GR SCALITDGR
## 26 430.20447 y4_ y_ 4 1 TDGR SCALITDGR
## 27 88.03931 b1 b 1 1 S SC[+57.02146]ALITDGR
## 28 248.06996 b2 b 2 1 SC SC[+57.02146]ALITDGR
## 29 319.10707 b3 b 3 1 SCA SC[+57.02146]ALITDGR
## 30 432.19113 b4 b 4 1 SCAL SC[+57.02146]ALITDGR
## 31 545.27519 b5 b 5 1 SCALI SC[+57.02146]ALITDGR
## 32 646.32287 b6 b 6 1 SCALIT SC[+57.02146]ALITDGR
## 33 761.34981 b7 b 7 1 SCALITD SC[+57.02146]ALITDGR
## 34 818.37127 b8 b 8 1 SCALITDG SC[+57.02146]ALITDGR
## 35 175.11895 y1 y 1 1 R SC[+57.02146]ALITDGR
## 36 232.14041 y2 y 2 1 GR SC[+57.02146]ALITDGR
## 37 347.16735 y3 y 3 1 DGR SC[+57.02146]ALITDGR
## 38 448.21503 y4 y 4 1 TDGR SC[+57.02146]ALITDGR
## 39 561.29909 y5 y 5 1 ITDGR SC[+57.02146]ALITDGR
## 40 674.38315 y6 y 6 1 LITDGR SC[+57.02146]ALITDGR
## 41 745.42026 y7 y 7 1 ALITDGR SC[+57.02146]ALITDGR
## 42 905.45091 y8 y 8 1 CALITDGR SC[+57.02146]ALITDGR
## 43 743.33924 b7_ b_ 7 1 SCALITD SC[+57.02146]ALITDGR
## 44 800.36070 b8_ b_ 8 1 SCALITDG SC[+57.02146]ALITDGR
## 45 329.15679 y3_ y_ 3 1 DGR SC[+57.02146]ALITDGR
## 46 543.28853 y5_ y_ 5 1 ITDGR SC[+57.02146]ALITDGR
## 47 656.37259 y6_ y_ 6 1 LITDGR SC[+57.02146]ALITDGR
## 48 727.40970 y7_ y_ 7 1 ALITDGR SC[+57.02146]ALITDGR
## 49 887.44035 y8_ y_ 8 1 CALITDGR SC[+57.02146]ALITDGR
## 50 157.10839 y1_ y_ 1 1 R SC[+57.02146]ALITDGR
## 51 214.12985 y2_ y_ 2 1 GR SC[+57.02146]ALITDGR
## 52 430.20447 y4_ y_ 4 1 TDGR SC[+57.02146]ALITDGR
## 53 88.03931 b1 b 1 1 S SCALIT[+79.966]DGR
## 54 191.04850 b2 b 2 1 SC SCALIT[+79.966]DGR
## 55 262.08561 b3 b 3 1 SCA SCALIT[+79.966]DGR
## 56 375.16967 b4 b 4 1 SCAL SCALIT[+79.966]DGR
## 57 488.25373 b5 b 5 1 SCALI SCALIT[+79.966]DGR
## 58 669.26741 b6 b 6 1 SCALIT SCALIT[+79.966]DGR
## 59 784.29435 b7 b 7 1 SCALITD SCALIT[+79.966]DGR
## 60 841.31581 b8 b 8 1 SCALITDG SCALIT[+79.966]DGR
## 61 175.11895 y1 y 1 1 R SCALIT[+79.966]DGR
## 62 232.14041 y2 y 2 1 GR SCALIT[+79.966]DGR
## 63 347.16735 y3 y 3 1 DGR SCALIT[+79.966]DGR
## 64 528.18103 y4 y 4 1 TDGR SCALIT[+79.966]DGR
## 65 641.26509 y5 y 5 1 ITDGR SCALIT[+79.966]DGR
## 66 754.34915 y6 y 6 1 LITDGR SCALIT[+79.966]DGR
## 67 825.38626 y7 y 7 1 ALITDGR SCALIT[+79.966]DGR
## 68 928.39545 y8 y 8 1 CALITDGR SCALIT[+79.966]DGR
## 69 766.28378 b7_ b_ 7 1 SCALITD SCALIT[+79.966]DGR
## 70 823.30524 b8_ b_ 8 1 SCALITDG SCALIT[+79.966]DGR
## 71 329.15679 y3_ y_ 3 1 DGR SCALIT[+79.966]DGR
## 72 623.25453 y5_ y_ 5 1 ITDGR SCALIT[+79.966]DGR
## 73 736.33859 y6_ y_ 6 1 LITDGR SCALIT[+79.966]DGR
## 74 807.37570 y7_ y_ 7 1 ALITDGR SCALIT[+79.966]DGR
## 75 910.38489 y8_ y_ 8 1 CALITDGR SCALIT[+79.966]DGR
## 76 157.10839 y1_ y_ 1 1 R SCALIT[+79.966]DGR
## 77 214.12985 y2_ y_ 2 1 GR SCALIT[+79.966]DGR
## 78 510.17047 y4_ y_ 4 1 TDGR SCALIT[+79.966]DGR
## 79 88.03931 b1 b 1 1 S SC[+57.02146]ALIT[+79.966]DGR
## 80 248.06996 b2 b 2 1 SC SC[+57.02146]ALIT[+79.966]DGR
## 81 319.10707 b3 b 3 1 SCA SC[+57.02146]ALIT[+79.966]DGR
## 82 432.19113 b4 b 4 1 SCAL SC[+57.02146]ALIT[+79.966]DGR
## 83 545.27519 b5 b 5 1 SCALI SC[+57.02146]ALIT[+79.966]DGR
## 84 726.28887 b6 b 6 1 SCALIT SC[+57.02146]ALIT[+79.966]DGR
## 85 841.31581 b7 b 7 1 SCALITD SC[+57.02146]ALIT[+79.966]DGR
## 86 898.33727 b8 b 8 1 SCALITDG SC[+57.02146]ALIT[+79.966]DGR
## 87 175.11895 y1 y 1 1 R SC[+57.02146]ALIT[+79.966]DGR
## 88 232.14041 y2 y 2 1 GR SC[+57.02146]ALIT[+79.966]DGR
## 89 347.16735 y3 y 3 1 DGR SC[+57.02146]ALIT[+79.966]DGR
## 90 528.18103 y4 y 4 1 TDGR SC[+57.02146]ALIT[+79.966]DGR
## 91 641.26509 y5 y 5 1 ITDGR SC[+57.02146]ALIT[+79.966]DGR
## 92 754.34915 y6 y 6 1 LITDGR SC[+57.02146]ALIT[+79.966]DGR
## 93 825.38626 y7 y 7 1 ALITDGR SC[+57.02146]ALIT[+79.966]DGR
## 94 985.41691 y8 y 8 1 CALITDGR SC[+57.02146]ALIT[+79.966]DGR
## 95 823.30524 b7_ b_ 7 1 SCALITD SC[+57.02146]ALIT[+79.966]DGR
## 96 880.32670 b8_ b_ 8 1 SCALITDG SC[+57.02146]ALIT[+79.966]DGR
## 97 329.15679 y3_ y_ 3 1 DGR SC[+57.02146]ALIT[+79.966]DGR
## 98 623.25453 y5_ y_ 5 1 ITDGR SC[+57.02146]ALIT[+79.966]DGR
## 99 736.33859 y6_ y_ 6 1 LITDGR SC[+57.02146]ALIT[+79.966]DGR
## 100 807.37570 y7_ y_ 7 1 ALITDGR SC[+57.02146]ALIT[+79.966]DGR
## 101 967.40635 y8_ y_ 8 1 CALITDGR SC[+57.02146]ALIT[+79.966]DGR
## 102 157.10839 y1_ y_ 1 1 R SC[+57.02146]ALIT[+79.966]DGR
## 103 214.12985 y2_ y_ 2 1 GR SC[+57.02146]ALIT[+79.966]DGR
## 104 510.17047 y4_ y_ 4 1 TDGR SC[+57.02146]ALIT[+79.966]DGRAdditional parameters can alter the type of ions produced or the
charge applied in calculateFragments. See
?calculateFragments for more details on those. See the
PTMods functions (?PTMods::convertAnnotation,
?PTMods::getCanonicalSequence,
?PTMods::combineModifications) for how to
handle/apply/change the annotation style of modifications on your
sequences or check out the corresponding vignette with
vignette("PTMods", package = "PTMods").
Visualising fragment ions
We can now visualise these fragments directly on the MS spectrum. Let’s first visualise the spectrum as is:
plotSpectra(sp1158[2])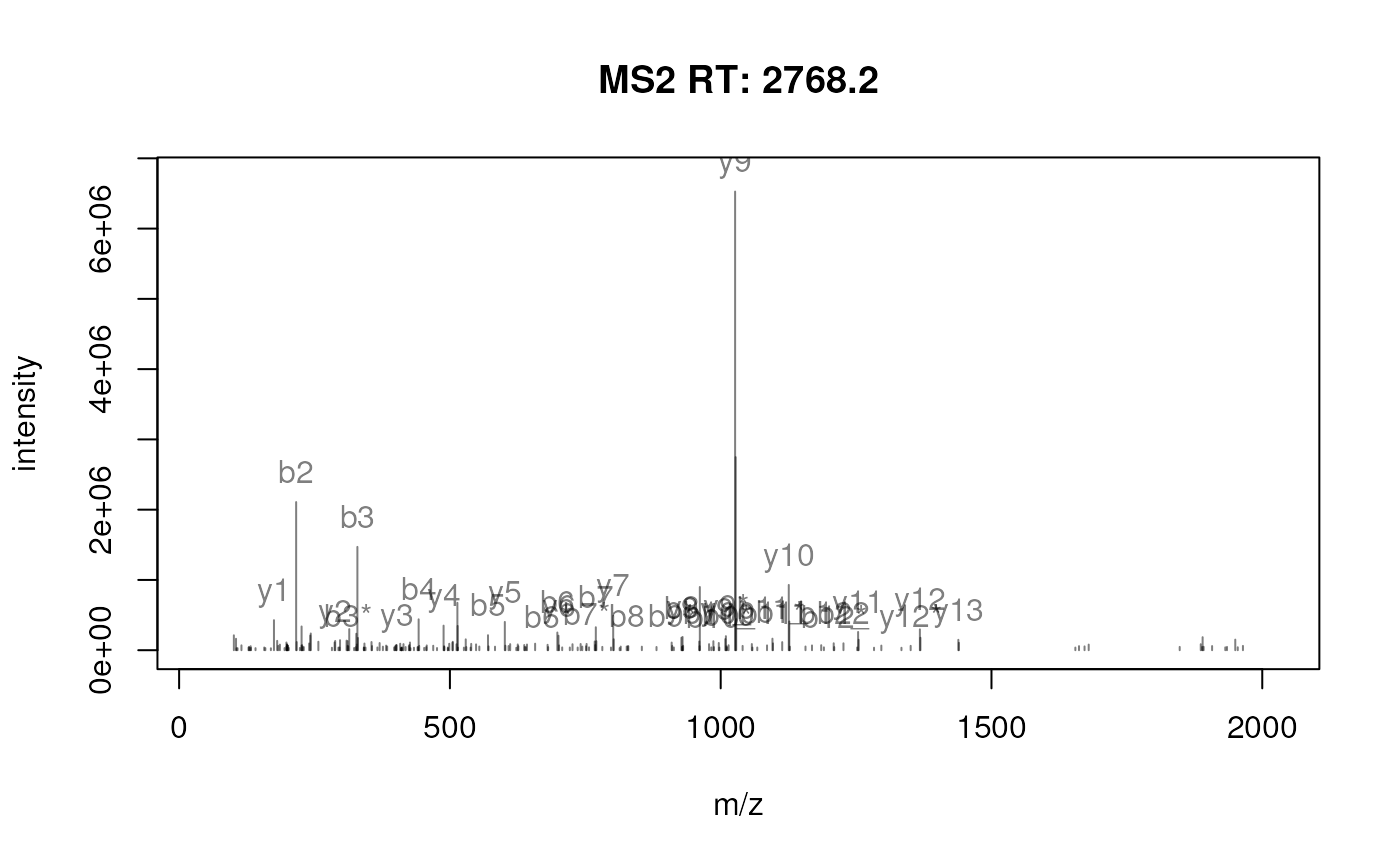
plotSpectraPTM() allows a more in depth visualisation of
a PSM by providing a delta mass plot of matched fragments and a direct
visualisation of matched b- and y-ion fragment sequences.
Labels are automatically applied based on the sequence
defined in the spectraVariables. Additionally, variable or
fixed modifications such as carbamidomethylation of cysteines can be
added using the variableModifications and
fixedModifications parameters. Remember, by default,
carbamidomethylation is applied on all sequences.
dataOrigin(sp1158)[2] <- "TMT_Erwinia" ## Reduces the mzspec text
plotSpectraPTM(sp1158[2],
fixedModifications = c(C = "Carbamidomethyl")
)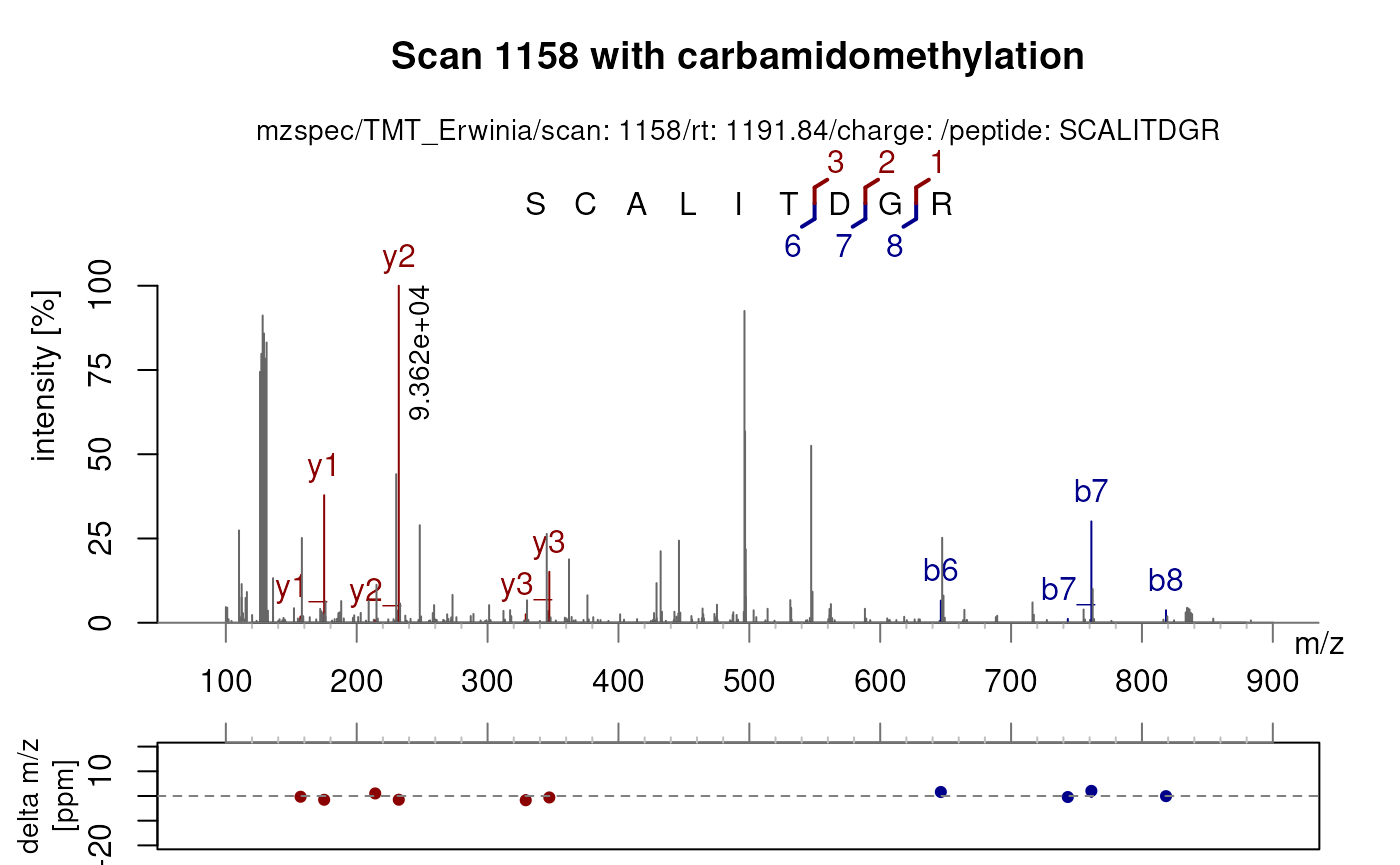
For instance, there is a better match when carbamidomethylation of cysteines is applied (as above) compared to no modifications at all.
plotSpectraPTM(sp1158[2],
variableModifications = c(C = "Carbamidomethyl"),
addCarbamidomethyl = FALSE, ## Remove carbamidomethyl by default
asp = 1/2,
deltaMz = FALSE,
main = c("Scan 1158 without carbamidomethyl", "Scan 1158 with carbamidomethyl")
)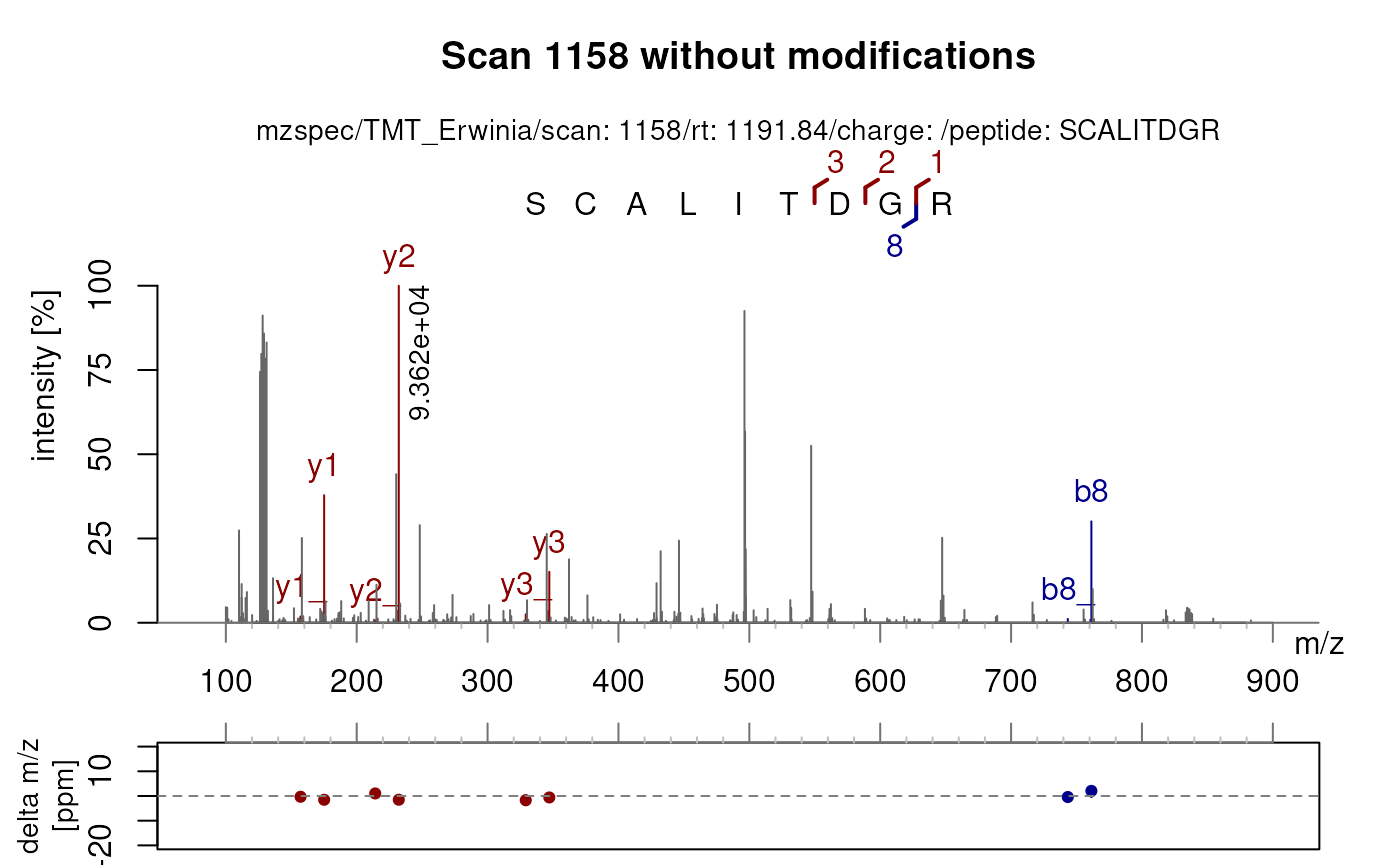
As glycine has the same mass as carbamidomethylation, the b7 and b8 ions are overlapping in both spectra.
Customising charge states
By default, plotSpectraPTM() generates fragments for all
charge states from 1 up to the precursor charge. You can customise this
behaviour using the z and allCharges
parameters.
The z parameter accepts a numeric vector with one value
per spectrum, specifying the charge state (or maximum charge state) to
use. The allCharges parameter controls whether to generate
fragments for all charges from 1 up to the specified value
(TRUE, the default) or only for the exact charge specified
(FALSE).
## Use fragments with a custom charge state
plotSpectraPTM(sp1158[2], z = 2, allCharges = FALSE)
## Use all charges from 1 to the precursor charge state or a custom charge
plotSpectraPTM(sp1158[2], z = 2, allCharges = TRUE)Note that z cannot be used simultaneously with
variableModifications.
The spectra displayed in this vignette might be overlapping due to the restricted windows. For a better visualisation, we suggest running the code locally.
For more details on what plotSpectraPTM() can do, run
?plotSpectraPTM.
Session information
## R version 4.6.0 (2026-04-24)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 24.04.4 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] Spectra_1.23.0 BiocParallel_1.47.0 MsDataHub_1.13.0
## [4] PSMatch_1.17.1 PTMods_1.1.1 S4Vectors_0.51.2
## [7] BiocGenerics_0.59.2 generics_0.1.4 BiocStyle_2.41.0
##
## loaded via a namespace (and not attached):
## [1] DBI_1.3.0 httr2_1.2.2
## [3] rlang_1.2.0 magrittr_2.0.5
## [5] clue_0.3-68 otel_0.2.0
## [7] matrixStats_1.5.0 compiler_4.6.0
## [9] RSQLite_3.52.0 png_0.1-9
## [11] systemfonts_1.3.2 vctrs_0.7.3
## [13] reshape2_1.4.5 stringr_1.6.0
## [15] ProtGenerics_1.45.0 pkgconfig_2.0.3
## [17] MetaboCoreUtils_1.21.1 crayon_1.5.3
## [19] fastmap_1.2.0 dbplyr_2.5.2
## [21] XVector_0.53.0 rmarkdown_2.31
## [23] ragg_1.5.2 purrr_1.2.2
## [25] bit_4.6.0 xfun_0.57
## [27] MultiAssayExperiment_1.39.0 cachem_1.1.0
## [29] jsonlite_2.0.0 blob_1.3.0
## [31] DelayedArray_0.39.2 parallel_4.6.0
## [33] cluster_2.1.8.2 R6_2.6.1
## [35] bslib_0.11.0 stringi_1.8.7
## [37] GenomicRanges_1.65.0 jquerylib_0.1.4
## [39] Rcpp_1.1.1-1.1 Seqinfo_1.3.0
## [41] bookdown_0.46 SummarizedExperiment_1.43.0
## [43] knitr_1.51 IRanges_2.47.1
## [45] Matrix_1.7-5 igraph_2.3.1
## [47] tidyselect_1.2.1 abind_1.4-8
## [49] yaml_2.3.12 codetools_0.2-20
## [51] curl_7.1.0 lattice_0.22-9
## [53] tibble_3.3.1 plyr_1.8.9
## [55] Biobase_2.73.1 withr_3.0.2
## [57] KEGGREST_1.53.0 evaluate_1.0.5
## [59] desc_1.4.3 BiocFileCache_3.3.0
## [61] ExperimentHub_3.3.0 Biostrings_2.81.1
## [63] pillar_1.11.1 BiocManager_1.30.27
## [65] filelock_1.0.3 MatrixGenerics_1.25.0
## [67] ncdf4_1.24 BiocVersion_3.24.0
## [69] glue_1.8.1 lazyeval_0.2.3
## [71] tools_4.6.0 AnnotationHub_4.3.0
## [73] data.table_1.18.4 mzR_2.47.0
## [75] QFeatures_1.23.1 fs_2.1.0
## [77] grid_4.6.0 tidyr_1.3.2
## [79] MsCoreUtils_1.25.4 AnnotationDbi_1.75.0
## [81] cli_3.6.6 rappdirs_0.3.4
## [83] textshaping_1.0.5 S4Arrays_1.13.0
## [85] dplyr_1.2.1 AnnotationFilter_1.37.0
## [87] sass_0.4.10 digest_0.6.39
## [89] SparseArray_1.13.2 htmlwidgets_1.6.4
## [91] memoise_2.0.1 htmltools_0.5.9
## [93] pkgdown_2.2.0.9000 lifecycle_1.0.5
## [95] httr_1.4.8 bit64_4.8.2
## [97] MASS_7.3-65