Chapter 3 Raw MS data
In this section, we will learn how to read raw data in one of the
commonly used open formats (mzML, mzXML, netCDF or mgf) into
R.
3.1 What is raw data in R
When we manipulate complex data, we need a way to abstract it.
The abstraction saves us from having to know about all the details of that data and its associated metadata. In R, we think of MS data as illustrated on the figure below (taken from (Gatto, Gibb, and Rainer 2020Gatto, Laurent, Sebastian Gibb, and Johannes Rainer. 2020. “MSnbase, Efficient and Elegant r-Based Processing and Visualisation of Raw Mass Spectrometry Data.” J. Proteome Res., September.)): a metadata table and a set of raw spectra. This allows to rely on a few easy-to-remember conventions to make mundane and repetitive tasks trivial and be able to complete more complex things easily. Abstractions provide a smoother approach to handle complex data using common patterns.
Figure 3.1: Schematic representation of what is referred to by raw data: a collection of mass spectra and a table containing spectrum-level annotations along the lines. Raw data are imported from one of the many community-maintained open standards formats (mzML, mzXML, mzData or ANDI-MS/netCDF).
3.1.1 The Spectra class
We are going to use the
Spectra package
as an abstraction to raw mass spectrometry data.
Spectra is part of the R for Mass Spectrometry
initiative. It
defines the Spectra class that is used as a raw data abstraction, to
manipulate MS data and metadata. The best way to learn about a data
structure is to create one by hand.
Let’s create a DataFrame4 As defined in the Bioconductor S4Vectors
package. containing MS levels, retention time, m/z and intensities
for 2 spectra:
spd <- DataFrame(msLevel = c(1L, 2L), rtime = c(1.1, 1.2))
spd$mz <- list(c(100, 103.2, 104.3, 106.5), c(45.6, 120.4, 190.2))
spd$intensity <- list(c(200, 400, 34.2, 17), c(12.3, 15.2, 6.8))
spd## DataFrame with 2 rows and 4 columns
## msLevel rtime mz intensity
## <integer> <numeric> <list> <list>
## 1 1 1.1 100.0,103.2,104.3,... 200.0,400.0, 34.2,...
## 2 2 1.2 45.6,120.4,190.2 12.3,15.2, 6.8And now convert this DataFrame into a Spectra object:
## MSn data (Spectra) with 2 spectra in a MsBackendMemory backend:
## msLevel rtime scanIndex
## <integer> <numeric> <integer>
## 1 1 1.1 NA
## 2 2 1.2 NA
## ... 16 more variables/columns.► Question
Explore the newly created object using
-
spectraVariablesto extract all the metadata variables. Compare these to the spectra variables available from the previous example. -
spectraDatato extract all the metadata. -
peaksDatato extract a list containing the raw data. -
[to create subsets.
3.1.2 Spectra from mzML files
Let’s now create a new object using the mzML data previously
downloaded and available in the mzf file.
## [1] "/home/lgatto/.cache/R/rpx/c83ad32ce6d20_TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzML"## MSn data (Spectra) with 7534 spectra in a MsBackendMzR backend:
## msLevel rtime scanIndex
## <integer> <numeric> <integer>
## 1 1 0.4584 1
## 2 1 0.9725 2
## 3 1 1.8524 3
## 4 1 2.7424 4
## 5 1 3.6124 5
## ... ... ... ...
## 7530 2 3600.47 7530
## 7531 2 3600.83 7531
## 7532 2 3601.18 7532
## 7533 2 3601.57 7533
## 7534 2 3601.98 7534
## ... 34 more variables/columns.
##
## file(s):
## c83ad32ce6d20_TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzML► Question
- Repeat the data manipulations above.
- Check the number of scans in the object with
length(). - Note the difference in the first line when showing the object in the console. We will get back to this idea of backend later.
Mass spectrometry data in Spectra objects can be thought of as a
list of individual spectra, with each spectrum having a set of
variables associated with it. Besides core spectra variables (such
as MS level or retention time) an arbitrary number of optional
variables can be assigned to a spectrum. The core spectra variables
all have their own accessor method and it is guaranteed that a value
is returned by it (or NA if the information is not available). The
core variables and their data type are (alphabetically ordered):
-
acquisitionNum
integer(1): the index of acquisition of a spectrum during a MS run. -
centroided
logical(1): whether the spectrum is in profile or centroid mode. -
collisionEnergy
numeric(1): collision energy used to create an MSn spectrum. -
dataOrigin
character(1): the origin of the spectrum’s data, e.g. the mzML file from which it was read. -
dataStorage
character(1): the (current) storage location of the spectrum data. This value depends on the backend used to handle and provide the data. For an in-memory backend like theMsBackendMemorythis will be"<memory>", for an on-disk backend such as theMsBackendHdf5Peaksit will be the name of the HDF5 file where the spectrum’s peak data is stored. -
intensity
numeric: intensity values for the spectrum’s peaks. -
isolationWindowLowerMz
numeric(1): lower m/z for the isolation window in which the (MSn) spectrum was measured. -
isolationWindowTargetMz
numeric(1): the target m/z for the isolation window in which the (MSn) spectrum was measured. -
isolationWindowUpperMz
numeric(1): upper m/z for the isolation window in which the (MSn) spectrum was measured. -
msLevel
integer(1): the MS level of the spectrum. -
mz
numeric: the m/z values for the spectrum’s peaks. -
polarity
integer(1): the polarity of the spectrum (0and1representing negative and positive polarity, respectively). -
precScanNum
integer(1): the scan (acquisition) number of the precursor for an MSn spectrum. -
precursorCharge
integer(1): the charge of the precursor of an MSn spectrum. -
precursorIntensity
numeric(1): the intensity of the precursor of an MSn spectrum. -
precursorMz
numeric(1): the m/z of the precursor of an MSn spectrum. -
rtime
numeric(1): the retention time of a spectrum. -
scanIndex
integer(1): the index of a spectrum within a (raw) file. -
smoothed
logical(1): whether the spectrum was smoothed.
For details on the individual variables and their getter/setter
function see the help for Spectra (?Spectra). Also note that these
variables are suggested, but not required to characterize a
spectrum. Also, some only make sense for MSn, but not for MS1 spectra.
In addition to the core spectra variables it is also possible to add additional
spectra variables to a Spectra object. As an example we add below a spectra
variable representing the retention times in minutes to the object. This
information can then be extracted again using the $ notation (similar to
accessing a column in a data.frame, i.e., $ and the name of the spectra
variable).
## [1] 0.00764000 0.01620833 0.03087333 0.04570667 0.06020667 0.07487500► Question
- Extract a set of spectra variables using the accessor (for example
msLevel(.)) or using the$notation (for example.$msLevel). - How many MS level are there, and how many scans of each level?
- Extract the index of the MS2 spectrum with the highest base peak intensity.
- Are the data centroided or in profile mode?
- Pick a spectrum of each level and visually check whether it is
centroided or in profile mode. You can use the
plotSpectra()function to visualise peaks and set the m/z range with thexlimarguments.
► Question
Using the first MS3TMT10 raw data file from MsDataHub , answer the
following questions:
- How many spectra are there in that file?
- How many MS levels, and how many spectra per MS level?
- What is the index of the MS2 spectrum with the highest precursor intensity?
- Plot one spectrum of each level. Are they centroided or in profile mode?
These objects and their manipulations are not limited to single files or
samples. Below we load data from two mzML files. The MS data from both files in
the Spectra is organized linearly (first all spectra from the first file
and then from the second). The dataOrigin function can be used to identify
spectra from the different data files.
## [1] "X20171016_POOL_POS_1_105.134.mzML" "X20171016_POOL_POS_3_105.134.mzML"## see ?MsDataHub and browseVignettes('MsDataHub') for documentation## loading from cache## see ?MsDataHub and browseVignettes('MsDataHub') for documentation## loading from cache## EH7809
## "/home/lgatto/.cache/R/ExperimentHub/31c07e7c0029cc_7859"
## EH7810
## "/home/lgatto/.cache/R/ExperimentHub/31c07e6f78fcc7_7860"##
## /home/lgatto/.cache/R/ExperimentHub/31c07e6f78fcc7_7860
## 931
## /home/lgatto/.cache/R/ExperimentHub/31c07e7c0029cc_7859
## 9313.1.3 Backends
Backends allow to use different backends to store mass spectrometry data while
providing via the Spectra class a unified interface to use that data. With
the setBackend function it is possible to change between different backends
and hence different data representations. The Spectra package defines a set of
example backends but any object extending the base MsBackend class could be
used instead. The default backends are:
-
MsBackendMzR: this backend keeps only general spectra variables in memory and relies on the mzR package to read mass peaks (m/z and intensity values) from the original MS files on-demand.
## MSn data (Spectra) with 1862 spectra in a MsBackendMzR backend:
## msLevel rtime scanIndex
## <integer> <numeric> <integer>
## 1 1 0.280 1
## 2 1 0.559 2
## 3 1 0.838 3
## 4 1 1.117 4
## 5 1 1.396 5
## ... ... ... ...
## 1858 1 258.636 927
## 1859 1 258.915 928
## 1860 1 259.194 929
## 1861 1 259.473 930
## 1862 1 259.752 931
## ... 34 more variables/columns.
##
## file(s):
## 31c07e7c0029cc_7859
## 31c07e6f78fcc7_7860-
MsBackendMemoryandMsBackendDataFrame: the full mass spectrometry data is stored (in-memory) within the object. Keeping the data in memory guarantees high performance but has also, depending on the number of mass peaks in each spectrum, a much higher memory footprint.
## MSn data (Spectra) with 1862 spectra in a MsBackendMemory backend:
## msLevel rtime scanIndex
## <integer> <numeric> <integer>
## 1 1 0.280 1
## 2 1 0.559 2
## 3 1 0.838 3
## 4 1 1.117 4
## 5 1 1.396 5
## ... ... ... ...
## 1858 1 258.636 927
## 1859 1 258.915 928
## 1860 1 259.194 929
## 1861 1 259.473 930
## 1862 1 259.752 931
## ... 34 more variables/columns.
## Processing:
## Switch backend from MsBackendMzR to MsBackendMemory [Fri Jun 26 09:33:31 2026]-
MsBackendHdf5Peaks: similar toMsBackendMzRthis backend reads peak data only on-demand from disk while all other spectra variables are kept in memory. The peak data are stored in Hdf5 files which guarantees scalability.
With the example below we load the data from a single mzML file and use a
MsBackendHdf5Peaks backend for data storage. The hdf5path parameter allows
us to specify the storage location of the HDF5 file.
## MSn data (Spectra) with 1862 spectra in a MsBackendHdf5Peaks backend:
## msLevel rtime scanIndex
## <integer> <numeric> <integer>
## 1 1 0.280 1
## 2 1 0.559 2
## 3 1 0.838 3
## 4 1 1.117 4
## 5 1 1.396 5
## ... ... ... ...
## 1858 1 258.636 927
## 1859 1 258.915 928
## 1860 1 259.194 929
## 1861 1 259.473 930
## 1862 1 259.752 931
## ... 34 more variables/columns.
##
## file(s):
## 31c07e7c0029cc_7859.h5
## 31c07e6f78fcc7_7860.h5
## Processing:
## Switch backend from MsBackendMzR to MsBackendHdf5Peaks [Fri Jun 26 09:33:35 2026]##
## /home/lgatto/.cache/R/ExperimentHub/31c07e6f78fcc7_7860
## 931
## /home/lgatto/.cache/R/ExperimentHub/31c07e7c0029cc_7859
## 931##
## /tmp/RtmpFqyrmq/31c07e6f78fcc7_7860.h5 /tmp/RtmpFqyrmq/31c07e7c0029cc_7859.h5
## 931 931All of the above mentioned backends support changing all of their their spectra
variables, except the MsBackendMzR that does not support changing m/z or
intensity values for the mass peaks.
Next to these default backends there are a set of other backend implementations
provided by additional R packages. The
MsBackendSql for
example allows to store (and retrieve) all MS data in (from) an SQL database
guaranteeing thus a minimal memory footprint.
Other backends focus on specific file formats such as
MsBackendMgf for files
in mgf file format or on specific acquisitions such as
MsBackendTimsTof
or provide access to certain MS data resources such as the
MsBackendMassbank.
Additional backends are being developed to address specific needs or
technologies, while remaining compliant with the Spectra interface.
If you would like to learn more about how the raw MS formats are
handled by Spectra via the mzR package,
check out the 7.1 section in the annex.
See also Spectra backends for more information on different backends, their properties and advantages/disadvantages.
3.2 Visualisation of raw MS data
The importance of flexible access to specialised data becomes visible
in the figure below (taken from the RforProteomics visualisation
vignette).
Not only can we access specific data and understand/visualise them,
but we can transverse all the data and extract/visualise/understand
structured slices of data.
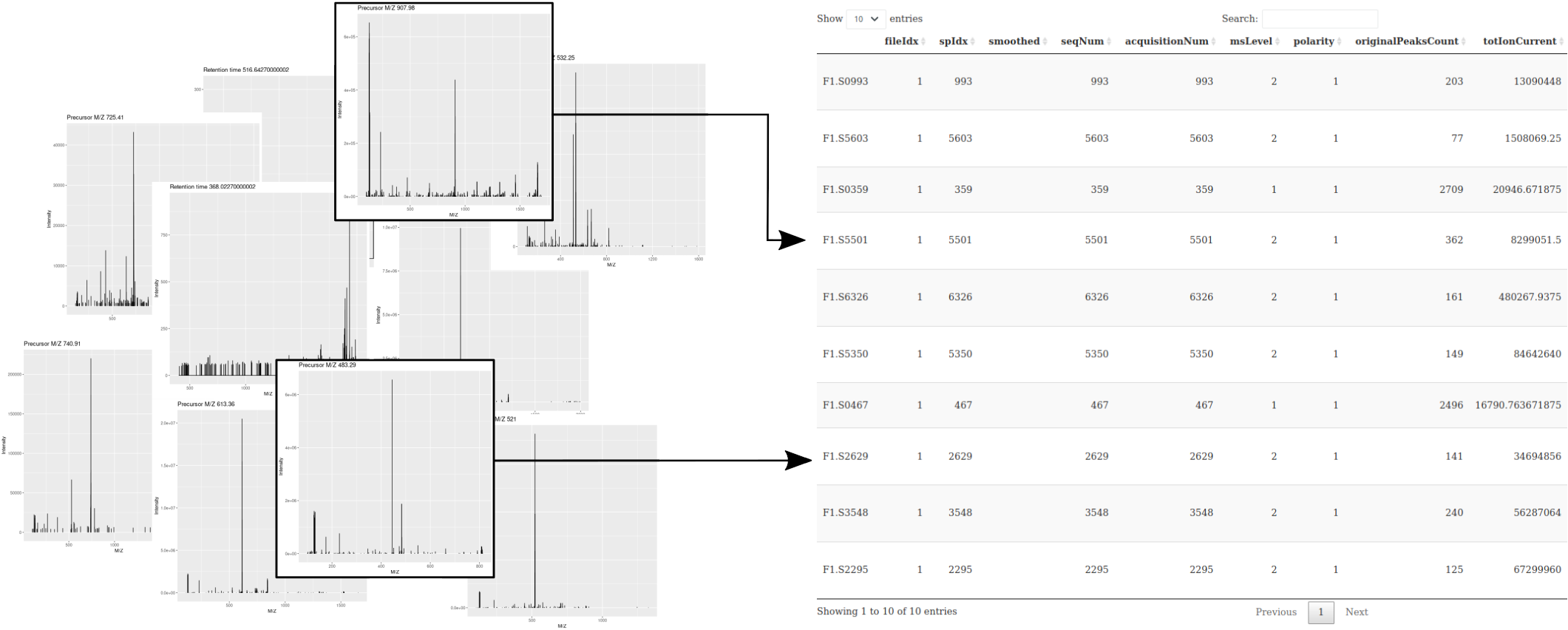
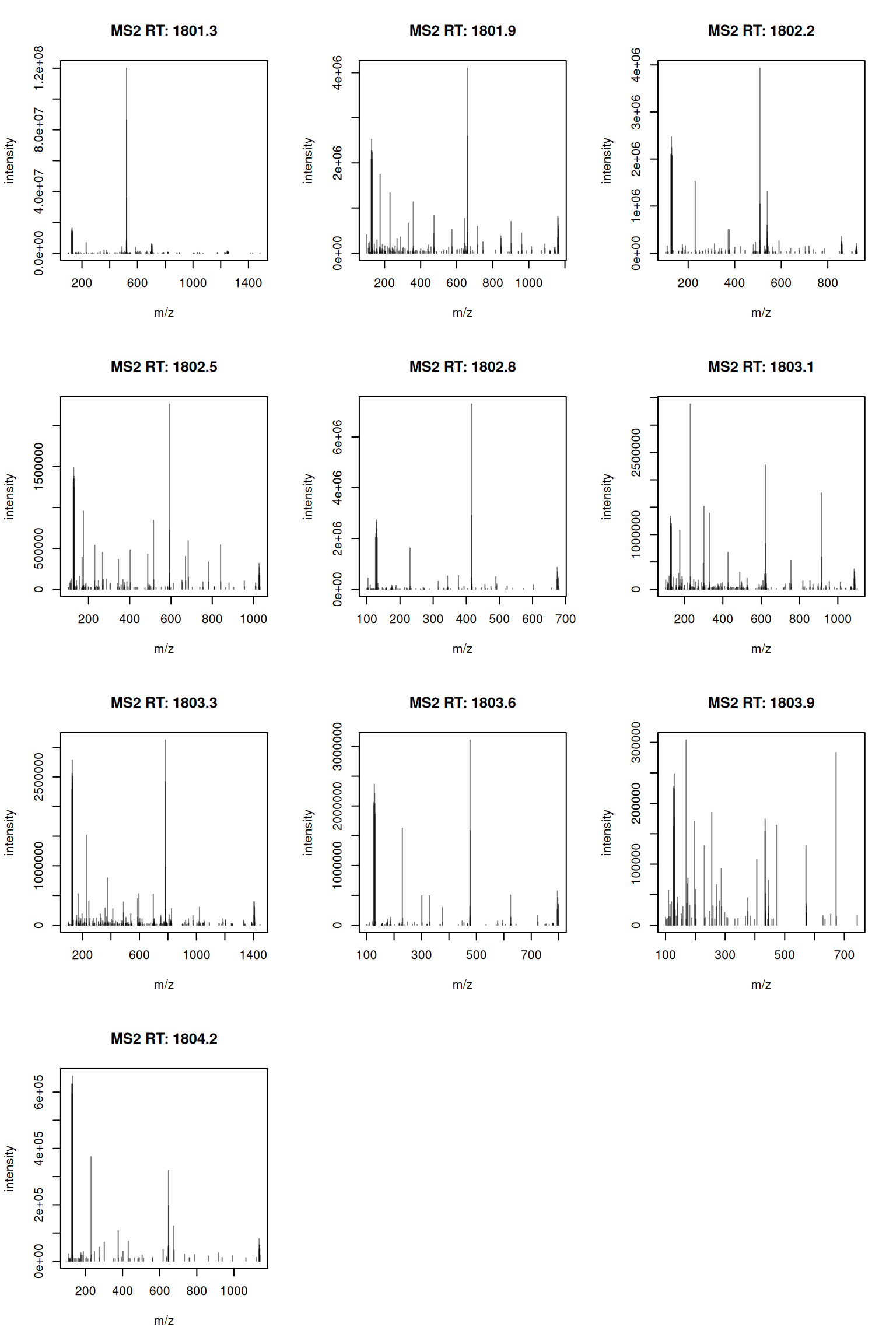
The figure below shows an illustration of how mass spectrometry works:
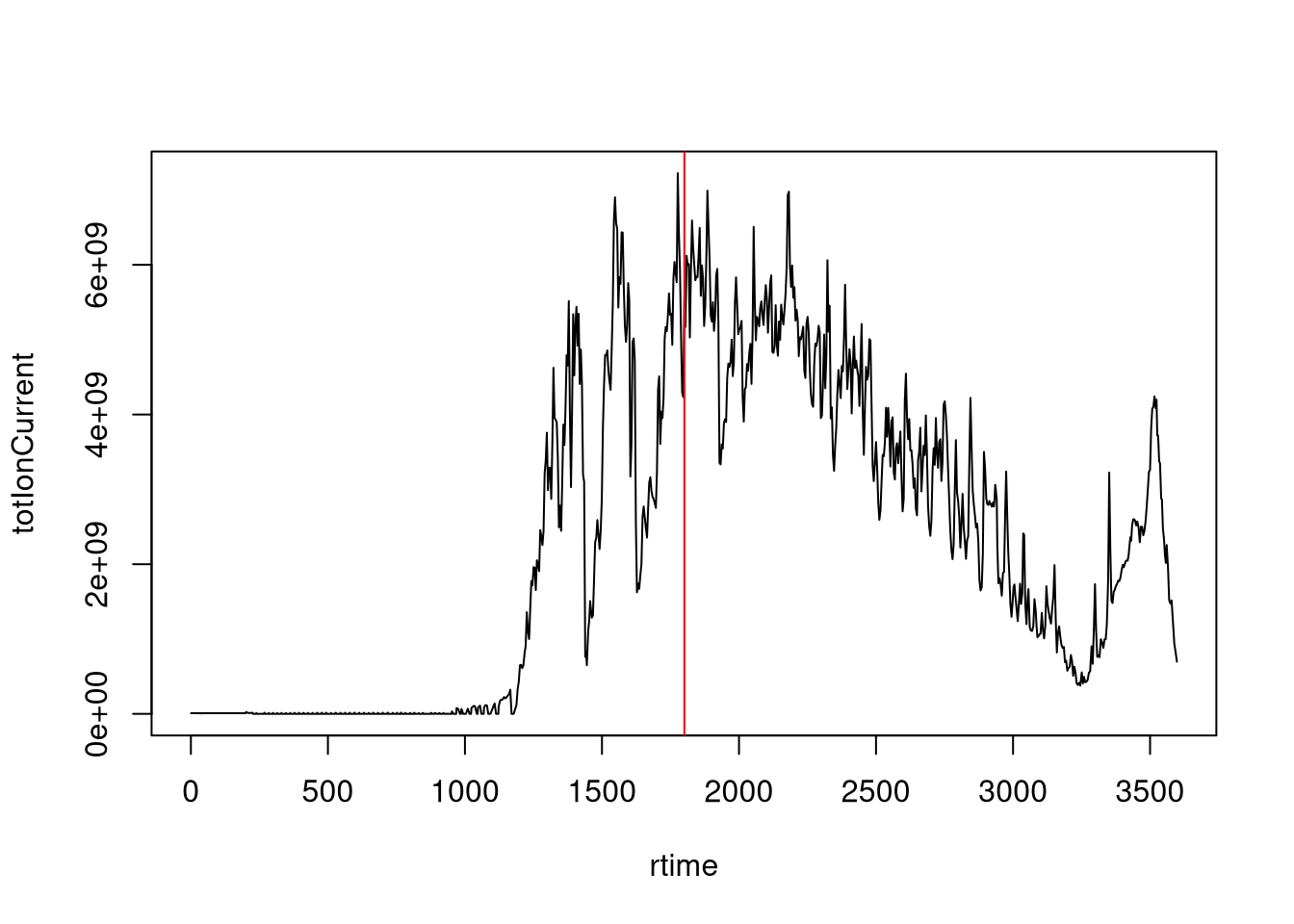
The chromatogram at the top displays the total ion current along the retention time. The vertical line identifies one scan in particular at retention time 1800.68 seconds (the 2807th scan).
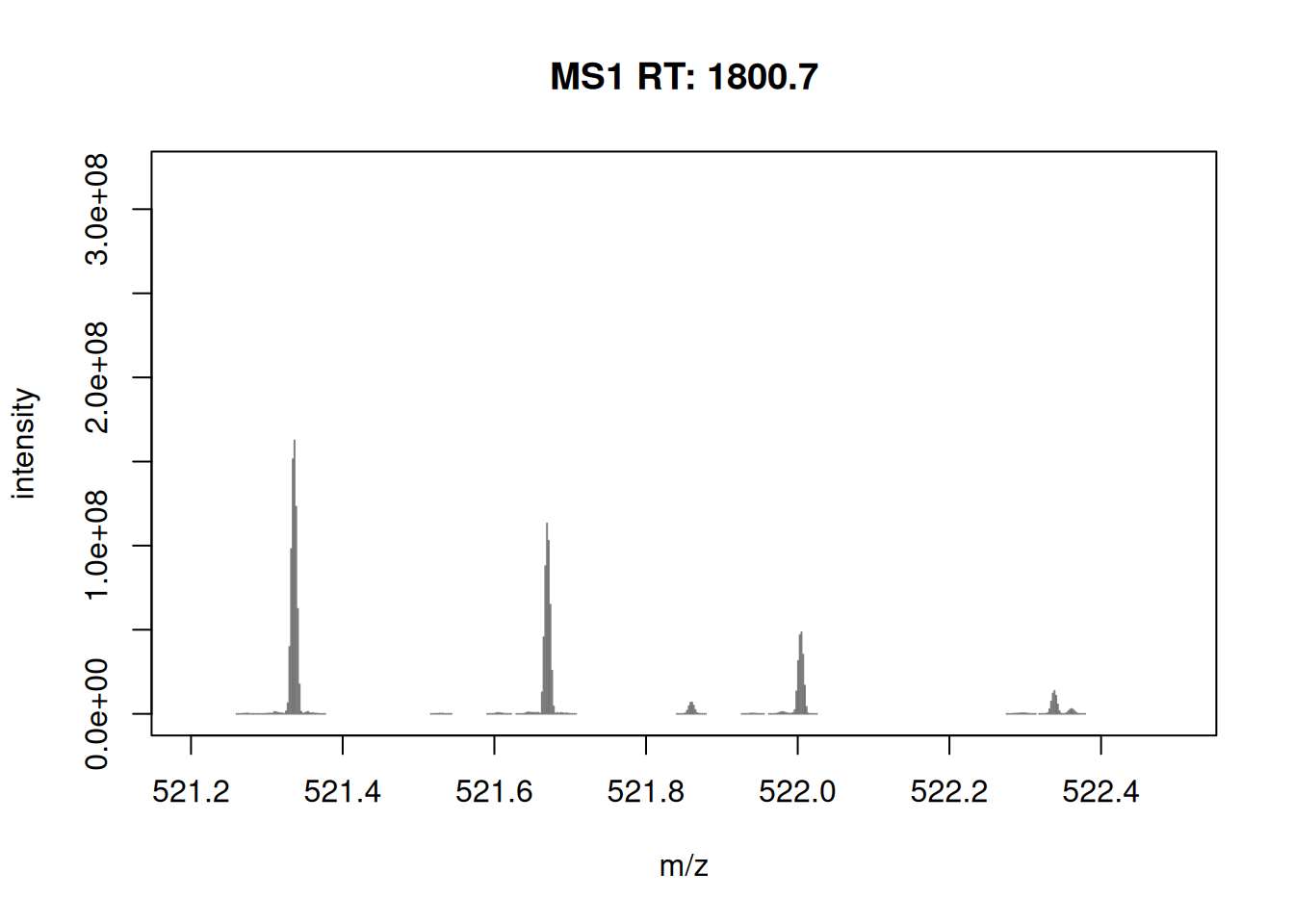
The spectra on the second line represent the full MS1 spectrum marked by the red line. The vertical lines identify the 10 precursor ions that where selected for MS2 analysis. The zoomed in on the right shows one specific precursor peak.
The MS2 spectra displayed along the two rows at the bottom are those resulting from the fragmentation of the 10 precursor peaks identified by the vertical bars above.
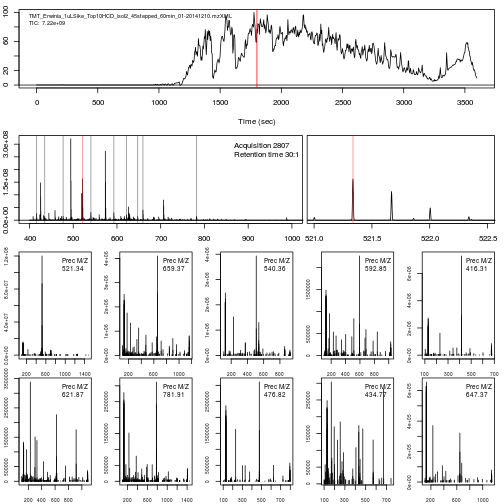
We are going to reproduce the figure above through a set of exercices.
► Question
- The chromatogram can be created by extracting the
totIonCurrentandrtimevariables for all MS1 spectra. Annotate the spectrum of interest.
► Solution
► Question
- The
filterPrecursorScan()function can be used to retain a set parent (MS1) and children scans (MS2), as defined by an acquisition number. Use it to extract the MS1 scan of interest and all its MS2 children.
► Solution
► Question
- Plot the MS1 spectrum of interest and highlight all the peaks that will be selected for MS2 analysis.
► Solution
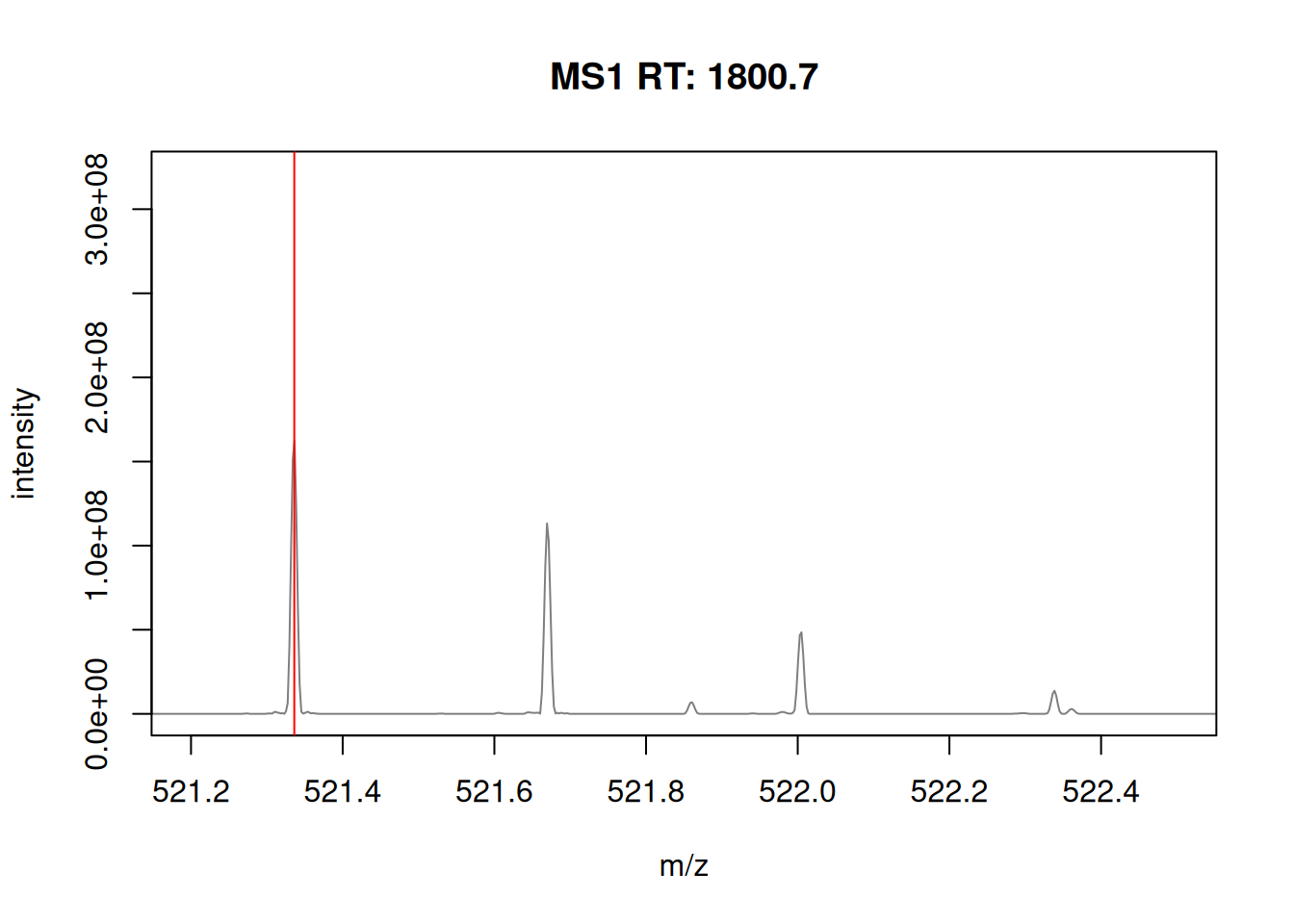
► Question
- Zoom in mz values 521.1 and 522.5 to reveal the isotopic envelope of that peak.
► Solution
► Question
- The
plotSpectra()function is used to plot all 10 MS2 spectra in one call.
► Solution
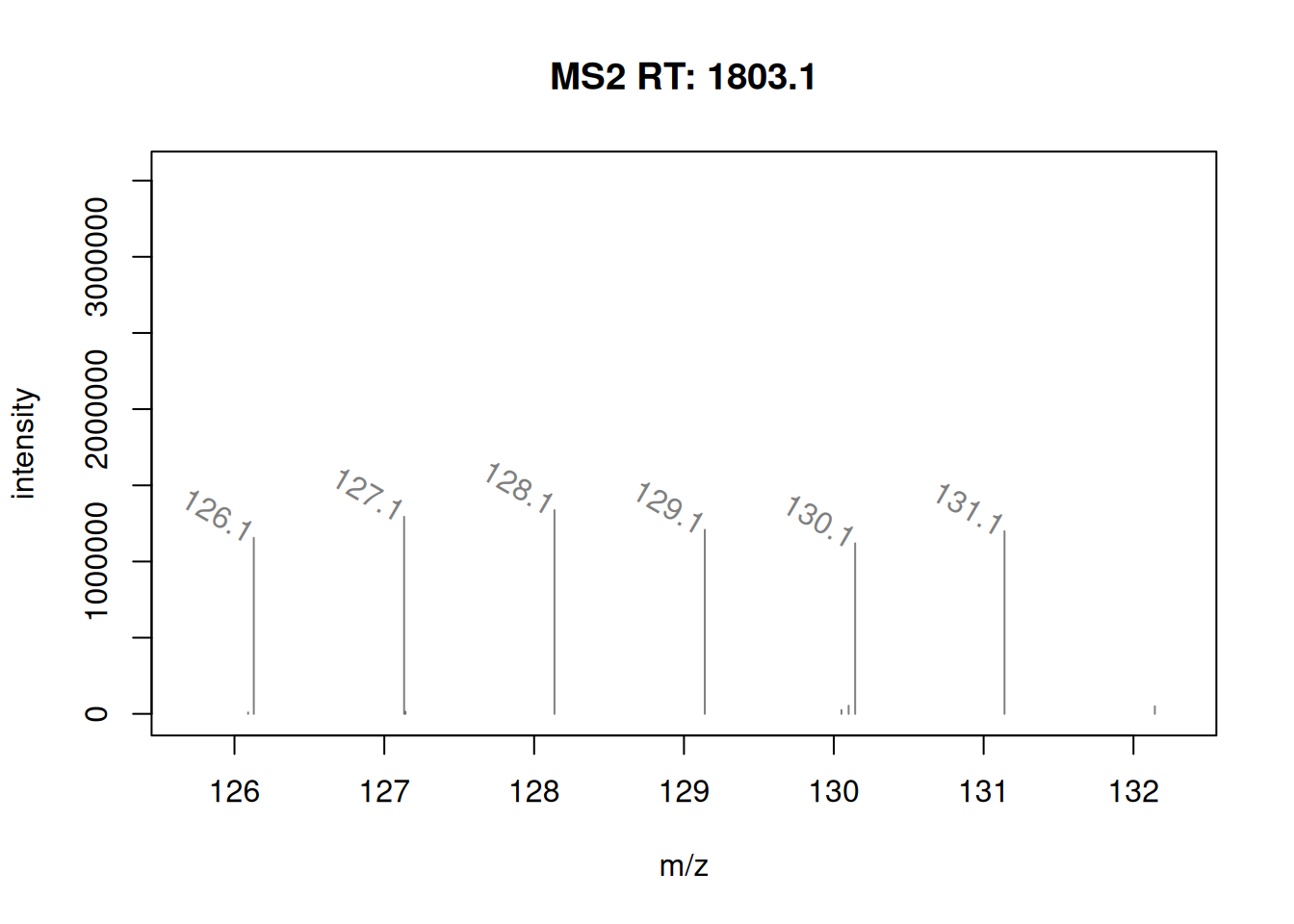
It is possible to label the peaks with the plotSpectra()
function. The labels argument is either a character of appropriate
length (i.e. with a label for each peak) or, as illustrated below, a
function that computes the labels.
mzLabel <- function(z) {
z <- peaksData(z)[[1L]]
lbls <- format(z[, "mz"], digits = 4)
lbls[z[, "intensity"] < 1e5] <- ""
lbls
}
plotSpectra(ms_2[7],
xlim = c(126, 132),
labels = mzLabel,
labelSrt = -30, labelPos = 2,
labelOffset = 0.1)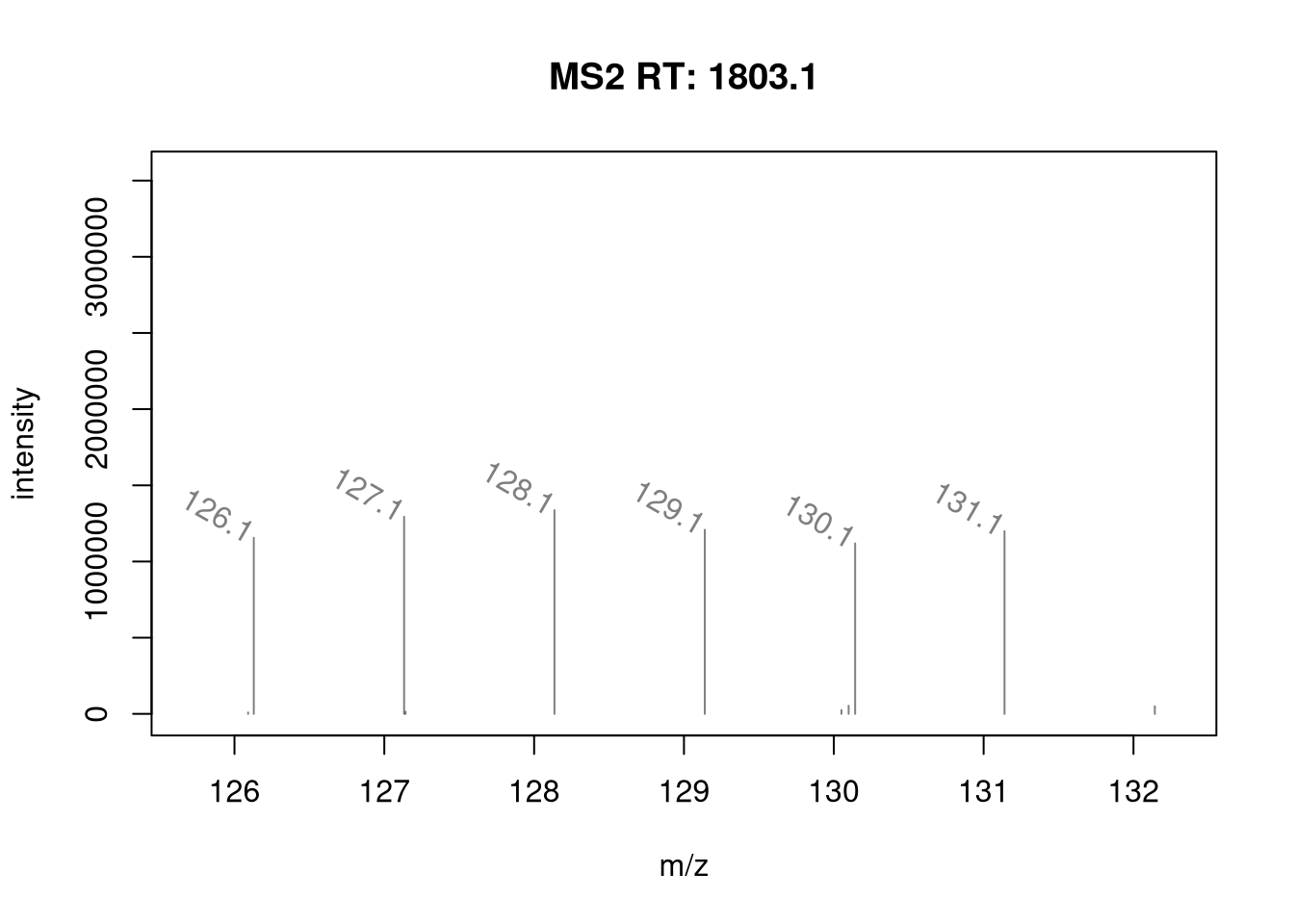
Spectra can also be compared either by overlay or mirror plotting
using the plotSpectraOverlay() and plotSpectraMirror() functions.
► Question
Filter MS2 level spectra and find any 2 MS2 spectra that have matching precursor peaks based on the precursor m/z values.
► Solution
► Question
Visualise the matching pair using the plotSpectraOverlay() and
plotSpectraMirror() functions.
► Solution
It is also possible to explore raw data interactively with the
SpectraVis
package:
The
browseSpectra()function opens a simple shiny application that allows to browse through the individual scans of a Spectra object.The
plotlySpectra()function displays a single spectrum usingplotlyallowing to explore (zooming, panning) the spectrum interactively.
► Question
Test the SpectraVis function on some the Spectra objects produce
above.
3.3 Raw data processing and manipulation
Apart from classical subsetting operations such as [ and split, a set of
filter functions are defined for Spectra objects that filter/reduce the number
of spectra within the object (for detailed help please see the ?Spectra help):
-
filterAcquisitionNum: retains spectra with certain acquisition numbers. -
filterDataOrigin: subsets to spectra from specific origins. -
filterDataStorage: subsets to spectra from certain data storage files. -
filterEmptySpectra: removes spectra without mass peaks. -
filterMzRange: subsets spectra keeping only peaks with an m/z within the provided m/z range. -
filterIsolationWindow: keeps spectra with the providedmzin their isolation window (m/z range). -
filterMsLevel: filters by MS level. -
filterPolarity: filters by polarity. -
filterPrecursorIsotopes: identifies precursor ions (from fragment spectra) that could represent isotopes of the same molecule. For each of these spectra groups only the spectrum of the monoisotopic precursor ion is returned. MS1 spectra are returned without filtering. -
filterPrecursorMaxIntensity: filters spectra keeping, for groups of spectra with similar precursor m/z, the one spectrum with the highest precursor intensity. All MS1 spectra are returned without filtering. -
filterPrecursorMzRange: retains (MSn) spectra with a precursor m/z within the provided m/z range. -
filterPrecursorMzValues: retains (MSn) spectra with precursor m/z value matching the provided value(s) considering also atoleranceandppm. -
filterPrecursorCharge: retains (MSn) spectra with speified precursor charge(s). -
filterPrecursorScan: retains (parent and children) scans of an acquisition number. -
filterRt: filters based on retention time range.
In addition to these, there is also a set of filter functions that operate on
the peak data, filtering and modifying the number of peaks of each spectrum
within a Spectra:
-
combinePeaks: groups peaks within each spectrum based on similarity of their m/z values and combines these into a single peak per peak group. -
deisotopeSpectra: deisotopes each individual spectrum keeping only the monoisotopic peak for peaks groups of potential isotopologues. -
filterIntensity: filter each spectrum keeping only peaks with intensities meeting certain criteria. -
filterMzRange: subsets peaks data within each spectrum keeping only peaks with their m/z values within the specified m/z range. -
filterPrecursorPeaks: removes peaks with either an m/z value matching the precursor m/z of the respective spectrum (with parametermz = "==") or peaks with an m/z value larger or equal to the precursor m/z (with parametermz = ">="). -
filterMzValues: subsets peaks within each spectrum keeping or removing (all) peaks matching provided m/z value(s) (given parametersppmandtolerance). -
reduceSpectra: filters individual spectra keeping only the largest peak for groups of peaks with similar m/z values.
► Question
Using the sp_sciex data, select all spectra measured in the second
mzML file and subsequently filter them to retain spectra measured
between 175 and 189 seconds in the measurement run.
► Solution
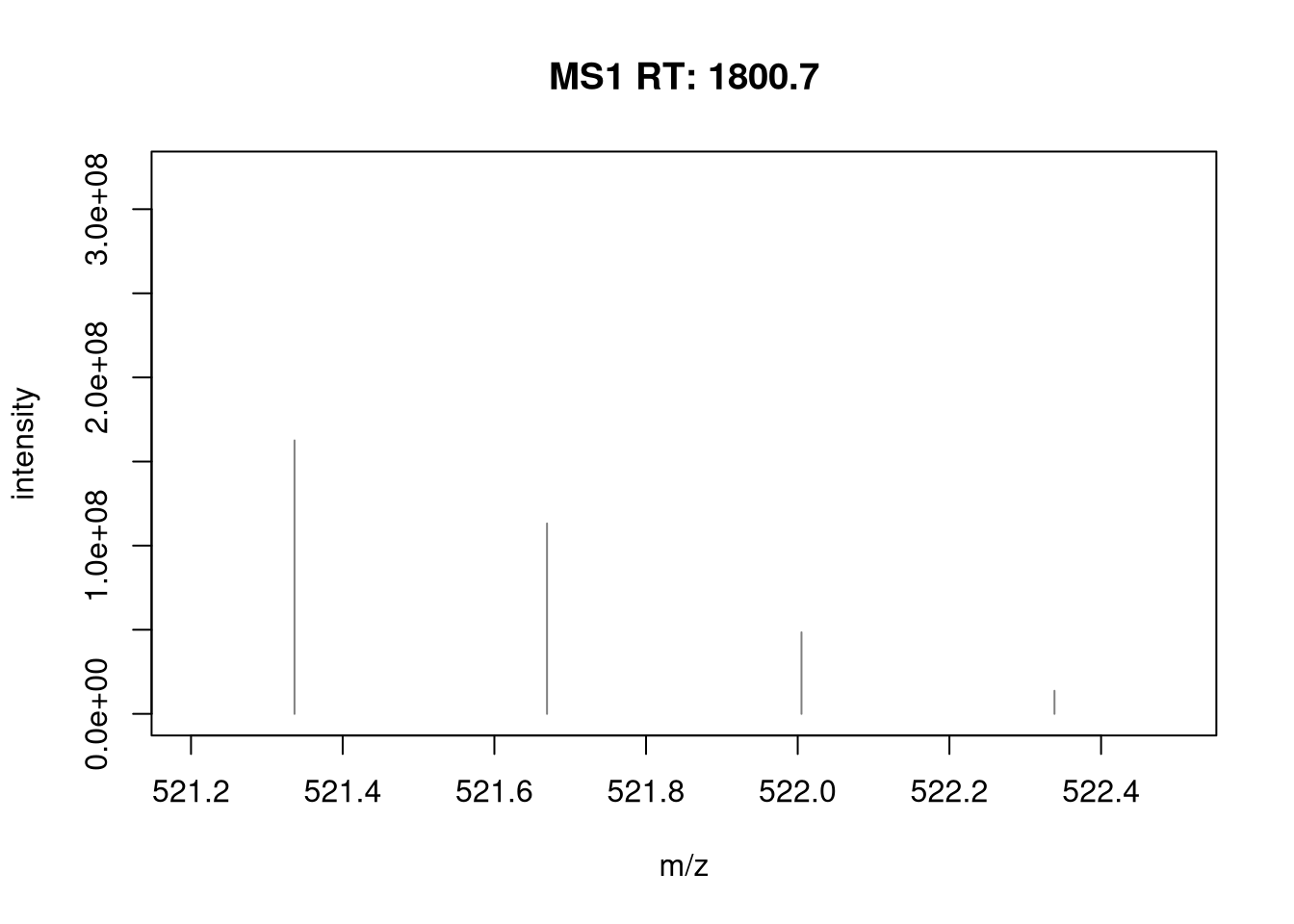
As an example of data processing, we use below the pickPeaks()
function. This function allows to convert profile mode MS data to centroid
mode data (a process also referred to as centroiding).
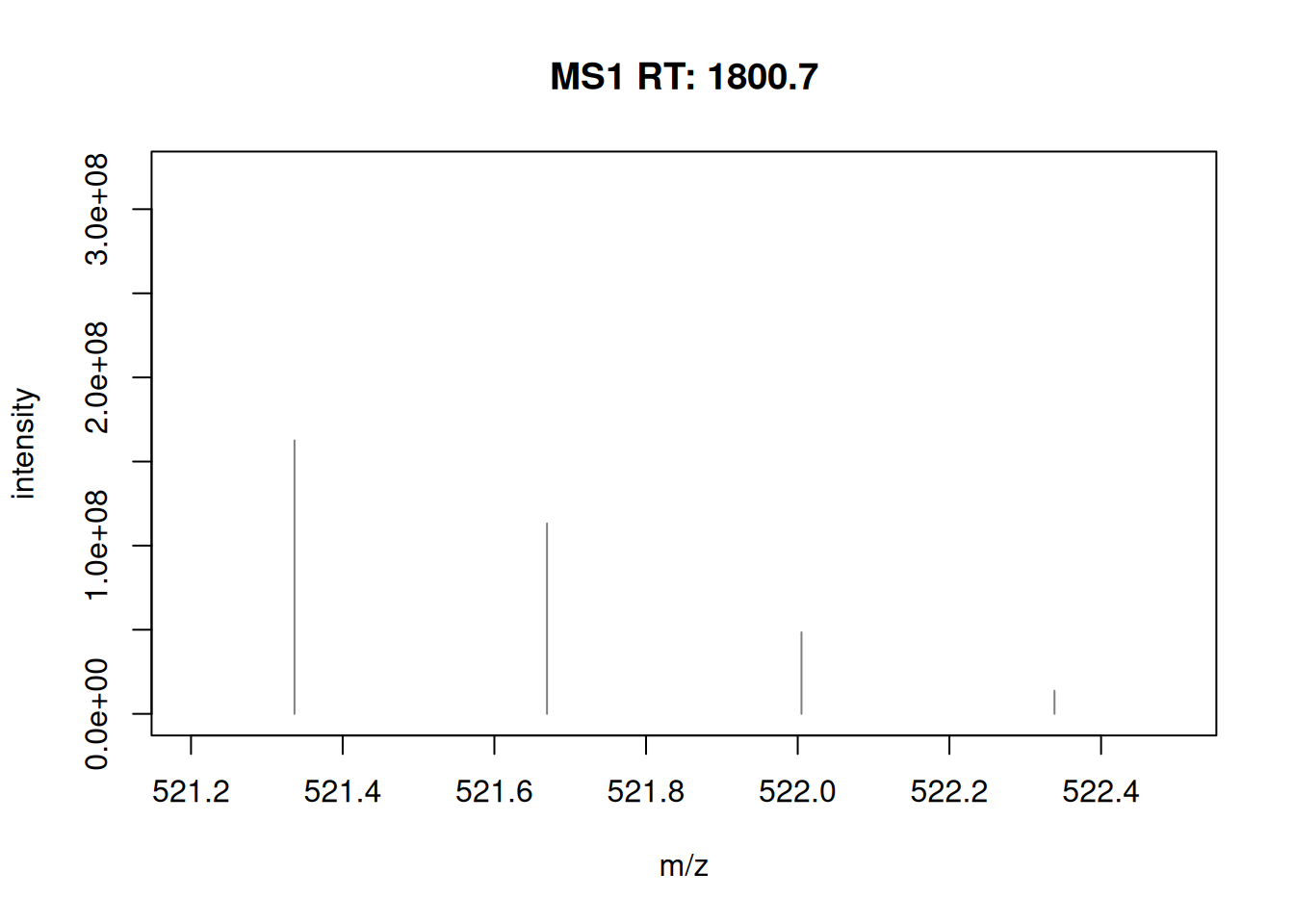
Centroiding reduces the profile mode MS data to a representative single mass peak per ion.
3.4 A note on efficiency
3.4.1 Backends
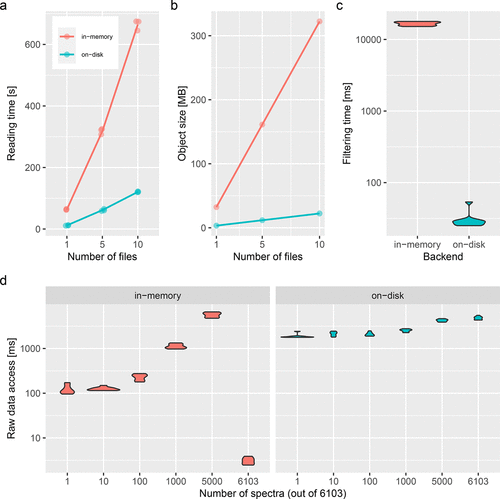
The figure below (taken from (Gatto, Gibb, and Rainer 2020Gatto, Laurent, Sebastian Gibb, and Johannes Rainer. 2020. “MSnbase, Efficient and Elegant r-Based Processing and Visualisation of Raw Mass Spectrometry Data.” J. Proteome Res., September.)) illustrates the respective
advantages of storing data in memory or on disk. The benchmarking was
done for the MSnbase package but also applies to the Spectra backends.
Figure 3.2: (a) Reading time (triplicates, in seconds) and (b) data size in memory (in MB) to read/store 1, 5, and 10 files containing 1431 MS1 (on-disk only) and 6103 MS2 (on-disk and in-memory) spectra. (c) Filtering benchmark assessed over 10 interactions on in-memory and on-disk data containing 6103 MS2 spectra. (d) Access time to spectra for the in-memory (left) and on-disk (right) backends for 1, 10, 100 1000, 5000, and all 6103 spectra. Benchmarks were performed on a Dell XPS laptop with an Intel i5-8250U processor 1.60 GHz (4 cores, 8 threads), 7.5 GB RAM running Ubuntu 18.04.4 LTS 64-bit, and an SSD drive. The data used for the benchmarking are a TMT 4-plex experiment acquired on a LTQ Orbitrap Velos (Thermo Fisher Scientific) available in the MsDataHub package.
3.4.2 Parallel processing
Most functions on Spectra support (and use) parallel processing out
of the box. Peak data access and manipulation methods perform by
default parallel processing on a per-file basis (i.e. using the
dataStorage variable as splitting factor). Spectra uses
BiocParallel for
parallel processing and all functions use the default registered
parallel processing setup of that package.
3.4.3 Lazy evaluation
Data manipulations on Spectra objects are not immediately applied to
the peak data. They are added to a so called processing queue which is
applied each time peak data is accessed (with the peaksData, mz or
intensity functions). Thanks to this processing queue data
manipulation operations are also possible for read-only backends
(e.g. mzML-file based backends or database-based backends). The
information about the number of such processing steps can be seen
below (next to Lazy evaluation queue).
## [1] 0sp_sciex <- filterIntensity(sp_sciex, intensity = c(10, Inf))
sp_sciex ## Note the lazy evaluation queue## MSn data (Spectra) with 1862 spectra in a MsBackendMzR backend:
## msLevel rtime scanIndex
## <integer> <numeric> <integer>
## 1 1 0.280 1
## 2 1 0.559 2
## 3 1 0.838 3
## 4 1 1.117 4
## 5 1 1.396 5
## ... ... ... ...
## 1858 1 258.636 927
## 1859 1 258.915 928
## 1860 1 259.194 929
## 1861 1 259.473 930
## 1862 1 259.752 931
## ... 34 more variables/columns.
##
## file(s):
## 31c07e7c0029cc_7859
## 31c07e6f78fcc7_7860
## Lazy evaluation queue: 1 processing step(s)
## Processing:
## Remove peaks with intensities outside [10, Inf] in spectra of MS level(s) 1. [Fri Jun 26 09:33:36 2026]## [1] 412## [[1]]
## Object of class "ProcessingStep"
## Function: user-provided function
## Arguments:
## o intensity = 10Inf
## o msLevel = 1Through this lazy evaluation system it is also possible to undo data manipulations:
## list()## [1] 0More information on this lazy evaluation concept implemented in Spectra is
provided in the Spectra
backends
vignette.
Page built: 2026-06-26 using R version 4.6.0 (2026-04-24)